神经网络取得了长足的进步,目前识别图像和声音的水平已经和人类相当,在自然语言理解方面也达到了很好的效果。但即使如此,讨论用机器来自动化人类任务看起来还是有些勉强。毕竟,我们做的不仅仅是识别图像和声音、或者了解我们周围的人在说什么,不是吗?
通过学习大数据文摘过去的文章,训练一个可以撰写文章并将数据科学概念以非常简单的方式向社区解释的人工智能作者
你不能从著名画家那里买到一幅名画。但你可不可以创造一个人工智能画家,通过从画家过去的作品中学习,然后像任何艺术家一样画画?
如果你感到被GAN的名字所,别担心,看完这篇科普文章你就会发现这不是一个高深莫测的东西。
在本文中,我将向您介绍GAN的概念,并解释其工作原理和面临的挑战。我还将让你了解人们使用GAN所做的一些很酷的事情,并提供一些重要资源的链接,以深入了解这些技术。

如果你想更加擅长某种东西,比如下棋,你会怎么做?你可能会和比你更强的对手对弈。你会分析你做错了什么、对方做对了什么,并思考下一场比赛如何才能击败他(她)。
你会重复这一步骤,直到你击败对手。这个概念可以被纳入到构建更好的模型中。所以简单来说,要获得一个强大的英雄(即生成器generator),我们需要一个更强大的对手(即鉴别器discriminator)。
伪造者的任务是模仿著名艺术家的画作。如果这个伪造的作品能够超越原始的作品,那么这个伪造者就可以卖出这张作品换很多钱。
另一方面,艺术品调查员的任务是抓住这些造假的伪造者。怎么做呢,他知道什么属性能把原作和赝品区分开来。通过检验手中的作品是否是真的,他可以评估自己的知识。
伪造者与调查员的竞赛继续进行,最终催生了世界级的调查员(很不幸以及世界级的伪造者)。 这是一场善与恶之间的斗争。
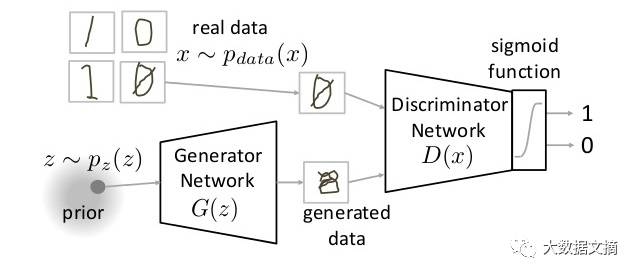
生成网络采用随机输入,尝试输出数据样本。在上述图像中,我们可以看到生成器G(z)从p(z)获取了输入z,其中z是来自概率分布p(z)的样本。生成器产生一个数据,将其送入鉴别器网络D(x)。鉴别网络的任务是接收真实数据或者生成数据,并尝试预测输入是真实还是生成的。它需要一个来自pdata(x)的输入x,其中pdata(x)是我们的真实数据分布。 D(x)然后使用Sigmoid函数解决二元分类问题,并输出0到1的值。
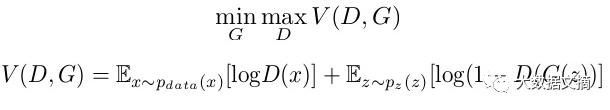
在我们的函数V(D,G)中,第一项是来自实际分布(pdata(x))的数据通过鉴别器(也称为最佳情况)的熵(Entropy)。鉴别器试图将其最大化为1。第二项是来自随机输入(p(z))的数据通过发生器的熵。生成器产生一个假样本, 通过鉴别器识别虚假(也称为最坏的情况)。在这一项中,鉴别器尝试将其最大化为0(即生成的数据是伪造的的概率的对数是0)。所以总体而言,鉴别器正在尝试最大化函数V(D,G)。
另一方面,生成器的任务完全相反,它试图最小化函数V(D,G),使真实数据和假数据之间的区别最小化。这就是说,生成器和鉴别器像在玩猫和老鼠的游戏。
第一阶段:训练鉴别器,冻结生成器(冻结意思是不训练,神经网络只向前,不进行Backpropagation反向)
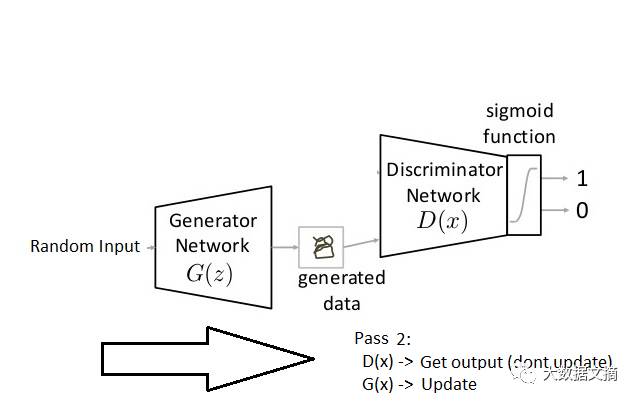
第2步:定义GAN的架构。GAN看起来是怎么样的,生成器和鉴别器应该是多层器还是卷积神经网络?这一步取决于你要解决的问题。
第3步:用真实数据训练鉴别器N个epoch。训练鉴别器正确预测真实数据为线到无穷大之间的任意自然数。
第5步:用鉴别器的出入训练生成器。当鉴别器被训练后,将其预测值作为标记来训练生成器。训练生成器来鉴别器。
第7步:手动检查假数据是否合理。如果看起来合适就停止训练,否则回到第3步。这是一个手动任务,手动评估数据是检查其假冒程度的最佳方式。当这个步骤结束时,就可以评估GAN是否表现良好。
喘口气,看一下这项技术有什么样的含义。假设你有一个功能完整的生成器,可以复制几乎任何东西。给你一些例子,你可以生成假新闻、不可思议的书籍和小说、自动应答服务等等。你可以拥有一个近乎现实的人工智能,一个真正的人工智能!这就是梦想。
你可能会问,如果我们知道这些美丽的生物()能做什么,为什么现在什么也没发生?这是因为我们还仅仅只接触到它的表面。在创造一个足够好的GAN的过程中有太多的障碍还没有清除。有一整个学术领域就是为了找出如何训练GAN。
训练GAN时最重要的障碍是稳定。你开始训练GAN,如果鉴别器比与其对应的发生器更强大,则发生器将无法有效训练。这反过来又会影响你的GAN的训练。另一方面,如果鉴别器过于宽松,理论上它可以允许生成器产生任何图像。这意味着你的GAN是无用的。
浏览GAN的稳定性的另一种方法是将其看做一个整体的问题。生成器和鉴别器都是相互竞争的,力求领先对方一步。此外,他们依赖彼此进行有效的培训。如果其中一个失败,整个系统就会失败。所以你必须确保它们不会崩掉。
这就像波斯王子游戏中的影子一样。你必须自己免受影子的袭击,它试图你。如果你你的影子,你会死;但如果你不做任何事情,你也一定会死!
计数问题:GAN无法区分特定对象在某个应发生的数量。正如我们在下面看到的,它在头上生成的眼睛个数比自然状态更多。

透视问题:GAN无法适应3D对象。它不理解视角,即前视图和后视图之间的差异。如下所示,它给出3D对象的平面(2D)展开。

全局结构问题:与透视问题相同,GAN不了解整体结构。例如,在左下角的图像中,它给出了一只四足牛的生成图像,即母牛站立在其后腿上,同时又站立在所有四条腿上。这在现实中绝对不可能!

大量的研究正被用来处理这些问题。很多比过去拥有更好结果的新模型被提出,比如DCGAN, WassersteinGan。
让我们实现一个简化的GAN来加强理论。我们将尝试通过在Identify the Digits数据集上训练GAN来生成数字。数据集包含了28x28的黑白图像,所有图像都是“.png”格式。我们的任务中只需要训练集。你可以在这里下载到数据: 。

注意:这是在论文中发表的GAN的第一个实现。在最近论文的伪码中可以看到许多改进和更新,例如在生成和鉴别网络中添加批量归一化(Batch Normalization),训练生成器k等。
我们了解了这些事情的工作原理,以及训练过程中的挑战。我们现在将要看到使用GAN完成的前沿研究。
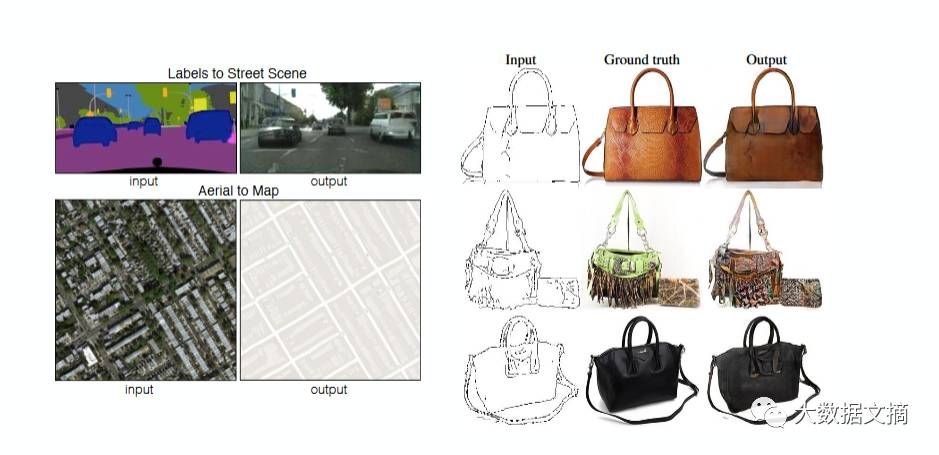
图像翻译:从一个图像生成另一个图像。例如,左边给出了带标签的街景,你可以用GAN生成真实的照片。在右边,给出简单的手提包绘画草稿,你会得到真正的手提包。
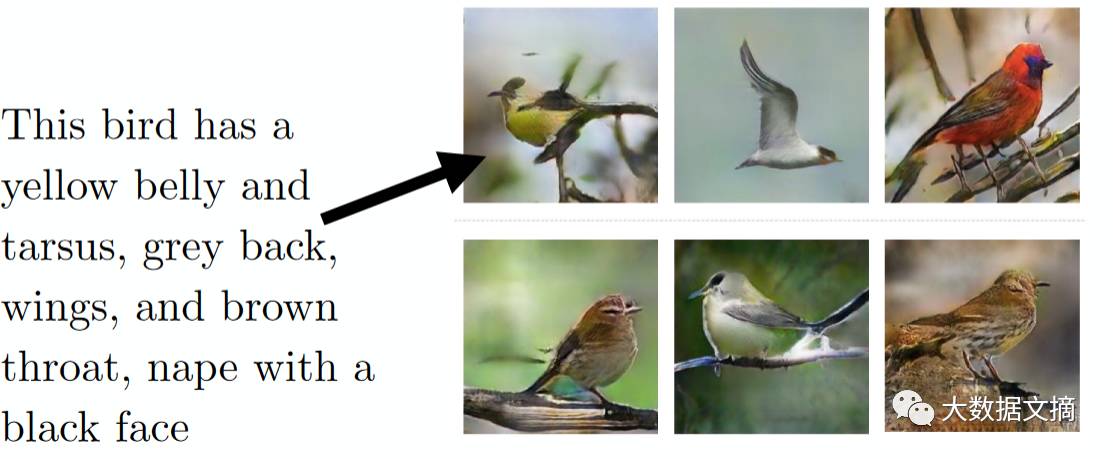
我希望你现在对未来感到兴奋,就像我第一次读到GAN时一样。它们将改变机器能为人类所做的事。想想吧,从准备新的食谱到创造图画,GAN拥有无限的可能性。
推荐: